Cách crawl dữ liệu web bằng Python
Cách crawl dữ liệu web hay cách thu thập dữ liệu web là một thắc mắc của khá nhiều bạn. Lý do bởi hiện nay, có vô vàn các website ở đủ mọi lĩnh vực cung cấp cho chúng ta rất nhiều thông tin hữu ích. Đôi khi, chúng ta sẽ muốn tổng hợp lại các thông tin này lại một chỗ để có thể dễ dàng sử dụng, phân tích,… Do vậy, bài viết này Lập Trình Không Khó sẽ hướng dẫn bạn các kiến thức cơ bản nhất về cách crawl (thu thập) dữ liệu web và có một vài demo bằng ngôn ngữ Python.
Để có thể nắm được tốt nhất nội dung của bài viết này, người đọc nên có sẵn 1 số kiến thức/kinh nghiệm sau:
- Nắm được cấu trúc của 1 website.
- Có kiến thức về HTML, CSS selector, XPath
- Có kiến thức căn bản về ngôn ngữ lập trình Python
- Có am hiểu nhất định về Dev Tools của trình duyệt
Nếu bạn không có sẵn các chuyên môn yêu cầu phía trên thì cũng không cần quá lo lắng. Bạn vẫn có thể nắm được cơ chế hoạt động, các kiến thức cơ bản và thực hành cùng tụi mình.
Lưu ý 1: Các kiến thức trong bài này áp dụng cho các website không áp dụng cơ chế lazy load. Thường sẽ là các website tin tức hay các website nhỏ. Trong khi đó khá nhiều website có cơ chế lazy load thì ngoài các kiến thức cơ bản trong bài viết này, ta sẽ cần các kỹ thuật nâng cao hơn.
Lưu ý 2: Trong quá trình thực hành, bạn chú ý tránh spam làm ảnh hưởng tới hoạt động bình thường của các website. Nếu cần, nên chạy vào ban đêm và để tốc độ vừa phải.
Chúng ta cùng bắt đầu nhé!
NỘI DUNG BÀI VIẾT
Kiến thức crawl dữ liệu web
Mã nguồn của trang (Page source)
Mọi web page của một trang web bất kỳ mà bạn nhìn thấy đều được trình duyệt vẽ lên từ 1 source code (bao gồm: html, css, js, json,…) mà máy chủ của website đó trả về cho trình duyệt.
Mỗi khi bạn yêu cầu xem 1 trang nào đó (ví dụ: truy cập url facebook.com), thì trình duyệt sẽ gửi yêu cầu đó về máy chủ. Máy chủ xử lý yêu cầu và gửi phản hồi lại là 1 source code (page source, do webserver sinh ra). Trình duyệt tiếp nhận page source này và hiển thị nội dung đẹp đẽ cho chúng ta coi.
Tất cả những gì trình duyệt hiện lên (cái chúng ta thấy) đều được lấy từ page source đó. Do vậy, về nguyên lý thì tất cả những gì bạn thấy trên trang web đều có thể thu thập được bằng ngôn ngữ lập trình.
Vậy, nếu chúng ta dùng ngôn ngữ lập trình để gửi yêu cầu tới một url nào đó, thì cái chúng ta nhận được cũng sẽ là page source. Và việc cần làm của chúng ta là tìm nội dung mình cần trong cái page source đó.
Lưu ý:
- Bạn có thể xem page source của 1 trang web bất kỳ bằng tổ hợp phím Ctrl + U hoặc kiểm tra phần tử bằng tổ hợp Ctrl + Shift + I. Với MacOS thì thay Ctrl bằng Cmd, bạn cũng có thể thấy chúng khi click chuột phải trên trang.
- Một số website sẽ chặn cách phía trên, ta vẫn có thể xem mã nguồn trên trình duyệt bằng cách truy cập địa chỉ: view-source:<url_cần_xem> như cách ta truy cập 1 trang web.
- Bạn cần có kiến thức cơ bản về HTML, CSS, JS để có thể hiểu mã nguồn này. Nếu không, bạn có thể thử tìm kiếm (Ctrl + F) từ khóa mình cần thử xem có không.
Mã nguồn của trang (page source) là dữ liệu có cấu trúc. Chúng ta hoàn toàn có thể biểu diễn nó dưới dạng cấu trúc dữ liệu Tree (cây). Qua đó, bạn có thể duyệt qua từng node trên cây, tìm kiếm và lấy giá trị của node bất kỳ trên cây đó.
Tìm kiếm phần tử
Khi có được mã nguồn của trang, chúng ta sẽ tìm kiếm đến những vị trí mà ta cần để lấy dữ liệu cần thiết. Quá trình đó có thể thực hiện bằng một số cách dưới đây:
Tìm kiếm theo CSS Selector
Nếu bạn đã từng dùng JS hoặc JQuery thì chắc không còn lạ với CSS Selector. Từ mã nguồn sau khi được “làm đẹp”, chúng ta có thể dùng css selector để đi tới phần tử chúng ta cần.
Lấy ví dụ một đoạn mã nguồn sau:
|
1 2 3 4 5 6 7 8 9 |
<div class="container"> <h3 id="top-site">Danh sách website</h3> <div class="item col-xs-6"> <p class="title">luyencode.net</p> </div> <div class="item col-xs-6"> <p class="title">nguyenvanhieu.vn</p> </div> </div> |
- Giá trị của các thuộc tính id (ex: top-site) thường sẽ là duy nhất trên mỗi webpage. Trong selecter thì class đại diện bởi dấu thăng (#) trước nó.
- Giá trị của các thuộc tính class (ex: container, item, col-xs-6) có thể lặp lại nhiều lần trên mỗi webpage. Trong selecter thì class đại diện bởi dấu chấm (.) trước nó.
- Các thẻ (ex: div, h3, p,…) là các tagname.
Ví dụ dùng css selector để tìm tới thẻ h3 có chứa giá trị Danh sách website:
- div.container > h3#top-site
- div > h3#top-site
- #top-site
Tìm kiếm theo XPath
Nếu coi page source là một file xml thì ta có cách tìm kiếm theo XPath. Ví dụ dùng css selector để tìm tới thẻ h3 (trong ví dụ trên) có chứa giá trị Danh sách website:
- /html/body/div/h3
- //*[@id=”top-site”]
Về cách này, mình không quá rành nên xin phép không bàn thêm.
Cách lấy CSS Selector/XPath của phần tử
Trên trình duyệt, bạn cũng có thể dễ dàng copy selector hoặc xpath bằng cách chuột phải vào phần tử tại Dev Tools (Ctrl + Shift + I) như hình dưới đây:
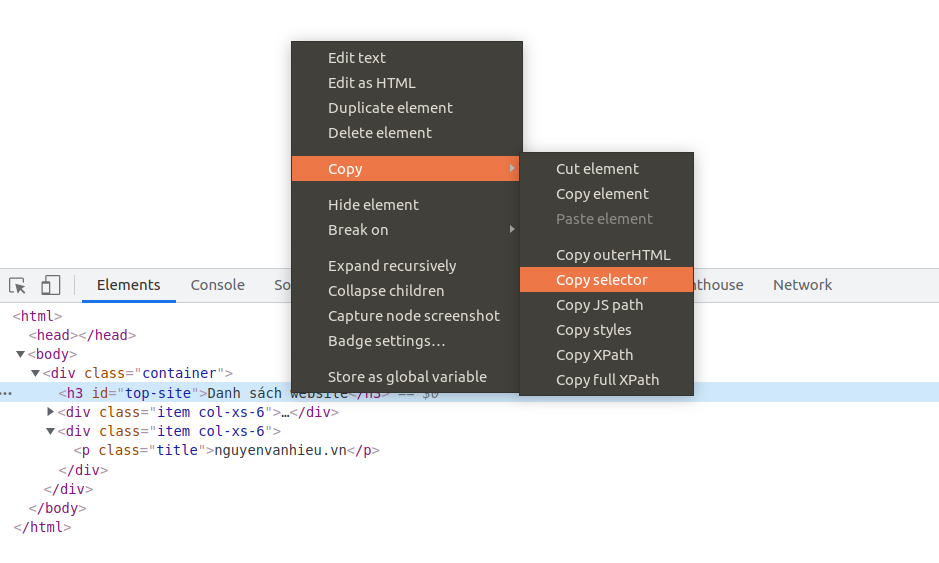
Xem gif để dễ hình dung hơn cách lấy xpath/css selector của một phần tử bất kỳ:

Quy trình: Đặt chuột vào phần tử cần lấy -> Click chuột phải -> Inspect -> Chuột phải vào source của nó -> Copy -> Copy Selector/Xpath.
Các thư viện crawl dữ liệu trong Python
Có thể nói, Python là ngôn ngữ đơn giản nhất giúp bạn có thể viết script crawl dữ liệu website nhanh chóng. Lý do bởi bản thân ngôn ngữ nó hỗ trợ rất tốt, lại còn kho tàng thư viện có sẵn hỗ trợ tận răng. Đó cũng là lý do mình chọn ngôn ngữ này để demo trong bài viết này.
# Thư viện requests
Với thư viện này, bạn có thể dễ dàng thực hiện gửi các yêu cầu (request) tới địa chỉ bất kỳ. Sau đó bạn sẽ nhận được phản hồi dưới dạng page source. Các chức năng cơ bản của thư viện này:
- Tạo request, có thể có tham số (url params, body params, …) theo method bất kỳ (GET, POST, …)
- Đọc phản hồi của máy chủ ở các format khác nhau (raw, json, media, …)
- Gửi kèm Cookies, Auth, …
- …
Thông tin thêm:
- Cài đặt: pip install requests
- Source: https://docs.python-requests.org/en/latest/
# Thư viện beautifulsoup4
Thư viện này sẽ hỗ trợ bạn “làm đẹp” cái source mà bạn nhận được mỗi khi gửi request. Sau khi làm đẹp, bạn có thể thực hiện mọi thao tác tìm kiếm, trích xuất giá trị mà mình cần tìm từ source.
Thông tin thêm:
- Cài đặt: pip install beautifulsoup4
- Source: https://www.crummy.com/software/BeautifulSoup/
# Dành cho website phức tạp
Với các website sử dụng cơ chế lazy load phức tạp. Các thành phần trên web chỉ yêu cầu tới máy chủ khi người dùng đang xem nó. Khi đó, một webpage mà bạn thấy được tạo ra bởi nhiều hơn 1 request (vd: Facebook, Instagram, …) đều có cơ chế này.
- selenium
- scrapy
Ưu điểm của các thư viện này là chúng giả lập trình duyệt luôn, nên không bỏ sót bất kỳ request nào. Nhưng như vậy ta phải tải tất cả nội dung mà có thể chẳng cần đến, dẫn đến quá trình thu thập sẽ chậm hơn nhiều.
Do đây là bài hướng dẫn cơ bản, mình sẽ không đi sâu vào dạng phức tạp này.
Thực hành thu thập dữ liệu web
Trong mục này, chúng ta sẽ cùng thực hành một vài ví dụ thực tế cách crawl dữ liệu web với ngôn ngữ Python.
# Vd1. Thu thập thông tin bài báo CNN
Trong ví dụ này, mình sẽ sử dụng ngôn ngữ Python và các thư viện requests, beautifulsoup để lấy các thông tin cần thiết từ 1 bài báo trên CNN.
- Cài các thư viện cần dùng: pip install requests beautifulsoup4 lxml
- Xem trước URL: https://edition.cnn.com/2021/10/03/uk/everard-uk-police-gbr-cmd-intl/index.html
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
import requests from bs4 import BeautifulSoup url = "https://edition.cnn.com/2021/10/03/uk/everard-uk-police-gbr-cmd-intl/index.html" # Gửi 1 request đến url phía trên và nhận lại source page của nó r = requests.get(url) print(r.status_code) # 200 là thành công # In thử page source ra coi sao, mình in thử 1000 ký tự đầu tiên thôi # Bạn có thể thử so sánh với source mà bạn thấy trên trình duyệt print(r.content[:1000]) # Làm đẹp source # Mình dùng lxml parser cho nhanh, # Ngoài ra có html.parser, lxml-xml, html5lib (https://www.crummy.com/software/BeautifulSoup/bs4/doc/) soup = BeautifulSoup(r.content, 'lxml') print("============TITLE=============") # Lấy thẻ tiêu đề bài báo print(soup.title) # Lấy nội dung tiêu đề print(soup.title.text) # Lấy ảnh đại diện của bài báo # Ta tìm selector của nó theo hướng dẫn ở trên rồi dùng hàm select_one để tìm 1 phần tử đầu tiên print("============FEATURE IMAGE=============") feature_image = soup.select_one('#large-media > div > img') print(feature_image.get('data-src-large')) # Lấy nội dung bài print("============CONTENT=============") # Mình kiểm tra phần tử thì thấy nội dung bài nằm trong section id="body-text" content_ele = soup.select_one("#body-text") print(content_ele.text) # Lấy tác giả bài viết, ngay phía dưới tiêu đề và phía trên ảnh đại diện # By Kara Fox, CNN print("============AUTHOR=============") author_ele = soup.select_one('body > div.pg-right-rail-tall.pg-wrapper > article > div.l-container > div.metadata > div > p.metadata__byline > span > a') print(author_ele.text) |
Kết quả thực thi:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
hieunv@hieunv:~/Documents/crawler$ python3 cnn.py 200 b'<!DOCTYPE html><html class="no-js"><head><meta content="IE=edge,chrome=1" http-equiv="X-UA-Compatible"><meta charset="utf-8"><meta content="text/html" http-equiv="Content-Type"><meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1.0"><link rel="dns-prefetch" href="/optimizelyjs/128727546.js" /><link rel="dns-prefetch" href="//tpc.googlesyndication.com" /><link rel="dns-prefetch" href="//pagead2.googlesyndication.com" /><link rel="dns-prefetch" href="//www.googletagservices.com" /><link rel="dns-prefetch" href="//partner.googleadservices.com" /><link rel="dns-prefetch" href="//www.google.com" /><link rel="dns-prefetch" href="//aax.amazon-adsystem.com" /><link rel="dns-prefetch" href="//c.amazon-adsystem.com" /><link rel="dns-prefetch" href="//cdn.krxd.net" /><link rel="dns-prefetch" href="//ads.rubiconproject.com" /><link rel="dns-prefetch" href="//optimized-by.rubiconproject.com" /><link rel="dns-prefetch" href="//fastlane.rubiconproject.com" /><link rel' ============TITLE============= <title>Sarah Everard was murdered by a UK police officer. Without urgent changes to policing, campaigners fear she won't be the last - CNN</title> Sarah Everard was murdered by a UK police officer. Without urgent changes to policing, campaigners fear she won't be the last - CNN ============FEATURE IMAGE============= //cdn.cnn.com/cnnnext/dam/assets/210314050931-04-vigil-sarah-everard-london-0313-super-169.jpg ============CONTENT============= (CNN)When thousands gathered to mourn the death of Sarah Everard, a 33-year-old woman who was kidnapped, raped and murdered in March, London police responded with force. Scenes of grieving women being pinned to the ground and brutalized by Metropolitan Police officers shocked people across the United Kingdom. Everard was just walking home when she was snatched from the street -- to the mourners it felt like it could have happened to them. They had gathered to "Reclaim These Streets," as the group that organized the vigil is called, and to honor a lost sister. But London's police called the event an illegal gathering and handcuffed some participants, citing Covid regulations. Prosecutors would later say Covid-19 rules were used by one of their own officers to detain and then kidnap Everard. On the night of March 3, Wayne Couzens, a serving Met police officer, spent the entire evening "hunting a lone female to kidnap and rape," according to the judge that sentenced him on Thursday. Couzens stopped Everard on the street by identifying himself as police, "arresting" her under the pretense of breaking Covid rules. He raped her later that evening and strangled her with his police belt. A week later, her remains were found in a woodland in Ashford, Kent -- more than 50 miles from where she was last seen. Everard is not the first woman to be killed by a British policeman. And campaigners fear she won't be the last. Read MoreSarah Everard's murderer kidnapped her using police ID and handcuffsAt least 16 women have been killed by serving or retired police officers over the last 13 years in the UK, according to the Femicide Census, a group that collects data on women killed by men, and campaigners feel that tackling gender-based violence is not a police priority. There are hundreds of allegations of gender-based violence by police officers every year. Nearly 700 domestic abuse allegations were launched against police officers and staff from April 2015-2017, according to a 2019 Bureau of Investigative Journalism investigation. It also found that domestic abuse at the hands of the police are treated differently in court, with just 3.9% of domestic abuse allegations among police in England and Wales ending in a conviction, compared with 6.2% among the general population. As fatal intimate partner violence is typically the culmination of years of abuse and coercive control, there is an urgent need to reform the criminal justice system, activists say. And that needs to start from the ground up. A woman attending the Sarah Everard vigil in south London on March 13, 2021 is arrested by police. Harriet Wistrich, solicitor and director of the Centre for Women's Justice (CWJ), told CNN that there is a "kind of boys' locker room type culture within policing, which means that often, officers are loyal to their fellow colleagues over and above undertaking proper investigations -- and that women are fearful of reporting to the police. And if they do, sometimes they're the ones that are victimized."The CWJ filed a "super complaint" to the UK police watchdog in 2019, highlighting the difficulties that around 150 domestic abuse survivors faced in trying to navigate a path to justice. This August, the Independent Office for Police Conduct published its findings, saying that the criminal justice system is failing to function effectively in responding to domestic abuse -- despite the government's claim that it's a priority. (The Domestic Violence Act, which was passed this spring, creates a statutory definition of domestic abuse and established the role of a domestic abuse commissioner.) Since the complaint was filed, more women have come forward with allegations about domestic violence by police, Wistrich said, allegations that fuel deeper concerns about gender-based violence in the force. Speaking outside the courthouse where Couzens was handed a rare whole life sentence on Thursday, Met Police Commissioner Cressida Dick -- who in June dismissed Couzens as an isolated "bad 'un," -- said that she was horrified that he had used a "position of trust to deceive and coerce Sarah." Dick apologized on behalf of the Met and acknowledged that trust in the police had been "shaken." She said as commissioner that she would "do everything in my power to ensure we learn any lessons." On the frontline with the British feminists trying to close the gap between rights and realitySix years ago, as an officer with the Kent Police force, Couzens was accused of indecent exposure. Three days before Everard's murder, he was accused of exposing himself at a fast food restaurant in south London. An investigation has since been opened into the alleged failures by the Met to investigate two allegations against Couzens of indecent exposure in February. Another investigation is looking into allegations that five serving officers and one former officer shared grossly offensive material with Couzens on a WhatsApp group in 2019. And a separate investigation was also opened into allegations that an officer taking part in the search for Everard shared an inappropriate graphic depicting violence against women in a WhatsApp group with colleagues at the time of her disappearance. Inappropriate behavior is not new in the force. In June 2020, after sisters Nicole Smallman and Bibaa Henry were brutally murdered in London, two Met police officers took selfies next to their bodies and shared them on WhatsApp. Six other officers failed to report it. There is no room for police officers with "question marks" over their previous conduct in the force, Wistrich said. People protest violence against women and a bill that would give police greater powers in Cardiff, Wales, on March 17. The Met said in a statement that Couzens had been vetted when he joined and had "no criminal convictions or cautions," but that: "Vetting is a snapshot in time and unfortunately, can never 100% guarantee an individual's integrity." But it also has a history of abetting sexual misconduct. As Couzens was sentenced on Thursday, a landmark judgment from the investigatory powers tribunal (IPT) ruled that the Met had violated an environmental activist's human rights after she had been deceived into a long-term sexual relationship by an undercover officer. Senior officers probably had a "a lack of interest in protecting women" from breaching their human rights and privacy, it said. The IPT ruling thrusts the spotlight onto other documented abuses of power in the force. From March 2017-2019, 415 referrals were made for officers that had abused their position to sexually assault someone, with domestic and sexual violence victims, sex workers and drug users most at risk of being abused by an on-duty police officer, according to a 2018 Her Majesty's Inspectorate of Constabulary and Fire & Rescue Services report. Nearly 500 Met police officers were accused of sexual misconduct, including assault and harassment from April 1, 2014-March 31, 2020, according to data released by a Freedom of Information request. Of the 493 complaints, 148 resulted in an investigation. Violence against women in the force is "not an isolated incident," says Wistrich. "It's something, much more kind of rotten within the system that that has to be rooted out."On Saturday, UK Prime Minister Boris Johnson described the police's failure to take violence against women and girls sufficiently seriously as "infuriating," in an interview with The Times. "Are the police taking this issue seriously enough? It's infuriating. I think the public feel that they aren't and they're not wrong," Johnson said."There is an issue about how we handle sexual violence, domestic violence, the sensitivity, the diligence, the time, the delay ... that's the thing we need to fix," he said," adding that the government is trying to "compress" the time between complaints being filed by women and at the point at which action is taken. Rape allegations continue to rise, but cases charged by the Crown Prosecution Service have dropped markedly, according to an October 2020 Victims Commissioner report, which said that in 2019-20 there were 55,000 reports of rape to the police, but only 1,867 cases charged. Plus, the proportion of survivors who chose to withdraw their case is on the rise (from 25% in 2015-16 to 41% in 2019-20). And the government's current strategy doesn't fill many women's rights activists with hope. The government has separated domestic abuse from their new Violence Against Women and Girls strategy, a move that many say misses the crucial point that women's experiences of violence and abuse are interconnected.In response to criticisms of the Met made in this article, a spokesperson told CNN in a statement: "There are numerous wide-ranging points here -- mostly the views of critics and commentators, and we're not setting out to knock back any criticisms they may wish to make."Disconnect and consentSince Couzens' sentencing, high-ranking police have been on a media blitz to signal they understand trust has been broken with the public, saying they will take steps to regain it. They've also outlined measures they believe women should take to feel safer. Women approached by lone police officers have a right to seek verification that the officer detaining them is legitimate, the Met said in a Friday statement.But that wouldn't have stopped Couzens from "arresting" Everard. He wasn't disguised as a police officer, he was a Met police officer -- with an officially issued warrant card to hand.The statement also said that if a woman has doubts about the validity of the arrest, they'd advise "running into a house, knocking on a door, waving a bus down" or calling police. Tributes to Sarah Everard are seen at Clapham Common on March 15 in London.Activists argue the police guidance is tone deaf, places the onus on women to take responsibility for avoiding crimes against them and shifts the focus away from the real problem: How to best identify and stamp out predators in their ranks. A member of Sisters Uncut, a direct-action feminist group who led the Everard vigil in March called the advice "ridiculous."Mirry, who asked CNN to be identified by her first name for safety, said that the Met's "advice shows the disconnect between the management of the police and the day-to-day experiences of the people who assumedly they serve."She added: "I think the focus of this advice is to make it seem as if Couzens was a cop gone rogue, when in fact we know that he was very much of part of a product of the institution."Activists also argue that crucially, such advice fails to take into consideration the concerns of people of color and minority backgrounds, who are disproportionately stopped by authorities in comparison to their White counterparts. They also say it's ableist, with police having not considered the rights of disabled people.London police warn women to be wary of lone officers after Sarah Everard murderThe Met's new guidance comes as the UK Home Secretary calls for an overhaul of policing. On Thursday, Priti Patel said that "all of us want to feel safe and be safe."Patel has also been backing a bill that will give more powers to the police, including tougher stop and search powers. For months, thousands have demonstrated against the Police, Crime, Sentencing and Courts Bill -- which is currently making its way through Parliament. The details of Everard's murder could add to that resistance. "There's a kind of myth in this country of policing by consent, that the police are able to exercise force over us because they have the confidence of the public because we consent to it," Mirry said, adding: "In the case of Sarah Reed (a victim of police brutality who died in prison) it's used to beat us up; in the case of Sarah Everard, it's used to kill us."We do not consent to have force used against us in the name of our own protection," she said. ============AUTHOR============= Kara Fox |
# Vd2. Thu thập tag phổ biến trên StackOverflow
- Cài các thư viện cần dùng: pip install requests beautifulsoup4 lxml
- Xem trước: https://stackoverflow.com/tags
- Với mỗi tag, mình sẽ lấy: tên tag, mô tả ngắn, số câu hỏi theo ngày, tuần và tổng số, số người theo dõi tag đó.
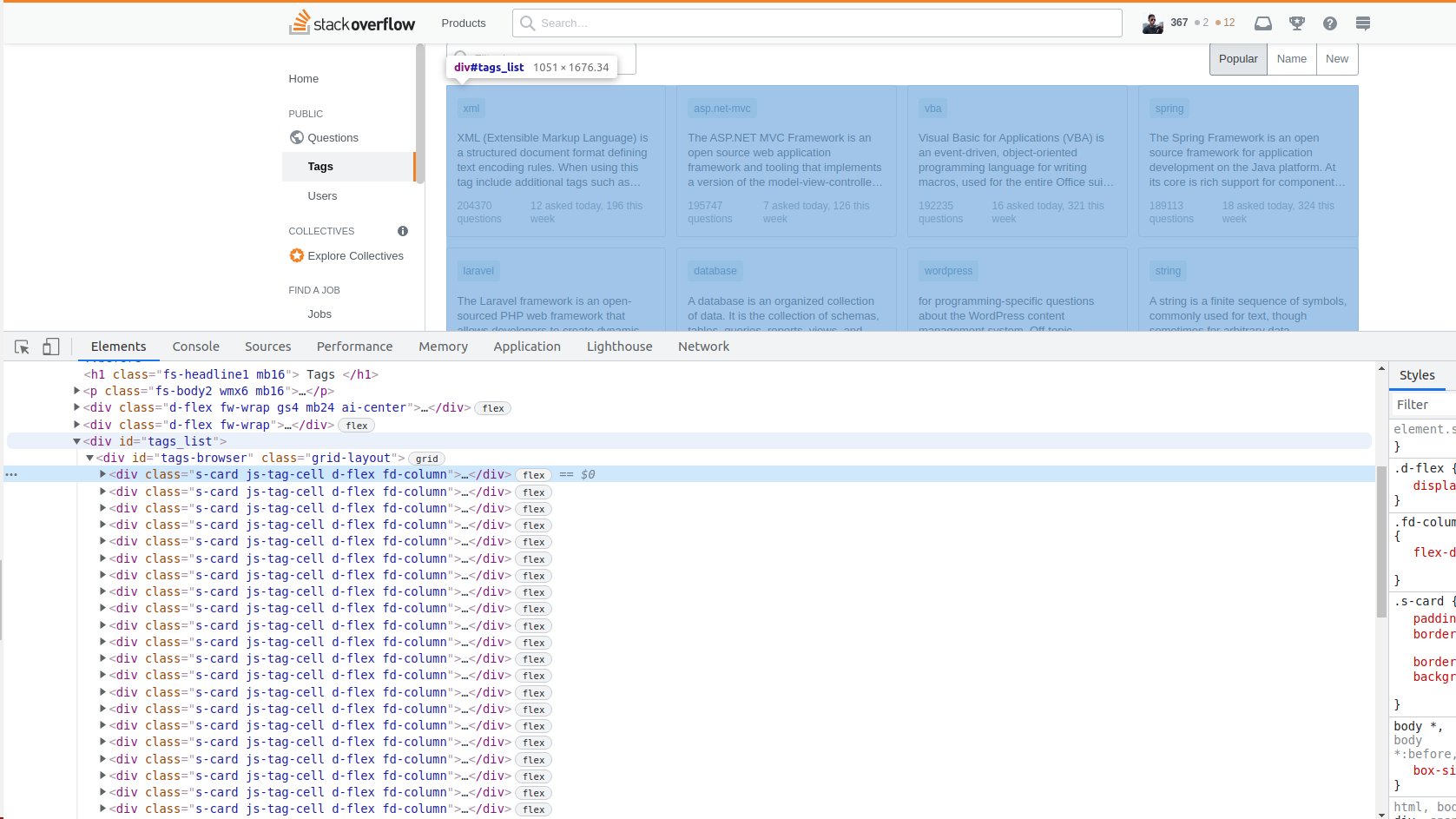
Source code kèm giải thích:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 |
import requests from bs4 import BeautifulSoup url = "https://stackoverflow.com/tags?page={}&tab=popular" page = 1 # Ý tưởng: # 1.Mình sẽ kéo page source của url về # 2. Làm đẹp source với bs4 # 3. Tìm tìm block chứa tất cả các block tag của page hiện tại # 4. Tìm tất cả các block tag, mỗi block là 1 tag # 5. Với mỗi block, ta viết 1 hàm để đọc các thông tin của nó # 1. Gửi request tới url với page được truyền vào r = requests.get(url.format(page)) print('status_code', r.status_code) # 2. Làm đẹp source soup = BeautifulSoup(r.content, 'lxml') # 3. Lấy block cha chứa tất cả các tags block_tag = soup.select_one('div#tags-browser') # 4. Các thẻ tag là con của block_tag, là các thẻ div có các class dưới đây all_tags = block_tag.select('div.s-card.js-tag-cell.d-flex.fd-column') print('Total tags count:', len(all_tags)) # 5. Viết hàm đọc các thông tin từ thẻ tag đó. # Nếu option xử lý được bật, mình sẽ bỏ qua các khoảng trắng thừa, chỉ lấy giá trị số lượng def get_tag_info(tag, preprocess=False): tag_name = tag.select_one('div.d-flex.jc-space-between.ai-center.mb12 > div > a').text tag_description = tag.select_one('div.flex--item.fc-medium.mb12.v-truncate4').text question_total = tag.select_one('div.mt-auto.d-flex.jc-space-between.fs-caption.fc-black-400 > div:nth-child(1)').text question_today = tag.select_one('div.mt-auto.d-flex.jc-space-between.fs-caption.fc-black-400 > div.flex--item.s-anchors.s-anchors__inherit > a:nth-child(1)').text question_this_week = tag.select_one('div.mt-auto.d-flex.jc-space-between.fs-caption.fc-black-400 > div.flex--item.s-anchors.s-anchors__inherit > a:nth-child(2)').text if preprocess: tag_description = tag_description.strip() question_total = question_total.split()[0] question_today = question_today.split()[0] question_this_week = question_this_week.split()[0] return tag_name, tag_description, question_total, question_today, question_this_week # Thử in ra mà ko xử lý print(get_tag_info(all_tags[0])) print() # Thử in ra và qua xử lý print(get_tag_info(all_tags[0], True)) # Ta có thể lấy toàn bộ bằng cách duyệt lần lượt # for tag in all_tags: # print(get_tag_info(tag, True)) |
Kết quả chạy:
|
1 2 3 4 5 6 |
hieunv@hieunv:~/Documents/crawler$ python3 stackoverflow.py status_code 200 Total tags count: 36 ('javascript', '\r\n For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Please include all relevant tags on your question; e.g., [node.js],…\r\n ', '2277839 questions', '471 asked today', '4511 this week') ('javascript', 'For questions regarding programming in ECMAScript (JavaScript/JS) and its various dialects/implementations (excluding ActionScript). Please include all relevant tags on your question; e.g., [node.js],…', '2277839', '471', '4511') |
# Vd3. Sử dụng Github API yêu cầu đăng nhập
- Cài đặt thư viện cần thiết: pip install requests
- Github API docs: https://docs.github.com/en/rest
- Để dùng Github API, ta cần phải đăng nhập để sử dụng. Do đó, ví dụ này mình sẽ demo cách dùng thư viện trong Python để đăng nhập (auth) của Github và lấy một số thông tin cá nhân trên Gihub của mình.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
import requests # Thay user, pass bằng username và pesonal access token của bạn r = requests.get('https://api.github.com/user', auth=('user', 'pass')) # Kiểm tra status_code print(r.status_code) print() # Lấy content-type mã request trả về từ header print(r.headers['content-type']) print() # Lấy encoding của response được trả về print(r.encoding) print() # Lấy kết quả trả về dạng text print(r.text) print() # Phía trên ta thấy content type là application/json. # Ta có thấy lấy về dạng dict như sau print(r.json()) |
Kết quả chạy:
|
1 2 3 4 5 6 7 8 9 |
200 application/json; charset=utf8 utf-8 {"type":"User"... # đoạn này là kiểu str {'private_gists': 219, 'total_private_repos': 7, ...} # đoạn này là kiểu dict |
# Ví dụ sử dụng Selenium
Với Selenium, nếu bạn đọc quan tâm có thể theo dõi các bài viết trong series Selenium không khó, series này bao gồm:
- Hướng dẫn cơ bản & cài đặt môi trường Selenium
- Ví dụ đăng nhập Facebook với Selenium
- Ví dụ lấy danh sách video của playlist bất kỳ
[sc_box]Lập Trình Không Khó có cung cấp dịch vụ thu thập & phân tích dữ liệu web, bạn đọc quan tâm có thể tham khảo chi tiết & liên hệ sử dụng dịch vụ TẠI ĐÂY [/sc_box]
Bài viết liên quan
- Khóa học lập trình Python
- Thu thập dữ liệu trang tin tức bất kỳ chỉ với 5 dòng code
- Phân loại văn bản tiếng Việt sử dụng machine learning
- Học nhanh Python trong 30 phút
Cảm ơn các bạn đã theo dõi bài viết hướng dẫn crawl dữ liệu website với Python. Trong quá trình tìm hiểu, thực hành. Nếu bạn đọc có thắc mắc thì có thể đặt câu hỏi tại:
- Facebook group: https://fb.com/groups/LapTrinhKhongKho
- Discord: https://discord.com/invite/hpeRrbccfZ
- Hoặc để lại bình luận phía dưới bài viết này

![[Khóa học tensorflow] Bài 5 – Xây dựng mô hình Neural Network](https://blog.luyencode.net/wp-content/uploads/2018/08/xay-dung-mo-hinh-neural-network-su-dung-tensorflow-768x432.png)
