LRU Cache là gì? Cách hoạt động và triển khai chi tiết
LRU Cache (Least Recently Used Cache) là một kỹ thuật quan trọng giúp tối ưu hiệu suất ứng dụng. Trong bài viết này, bạn sẽ tìm hiểu cách hoạt động của LRU Cache, cùng với ví dụ thực tế và hướng dẫn triển khai chi tiết từ góc nhìn của một kỹ sư phần mềm.
LRU Cache là gì?
LRU Cache là một cấu trúc dữ liệu được thiết kế để lưu trữ một số lượng giới hạn các item, trong đó các item ít được sử dụng gần đây nhất sẽ bị loại bỏ đầu tiên khi cache đầy. Đây là một trong những thuật toán cache phổ biến nhất và được sử dụng rộng rãi trong nhiều hệ thống thực tế.
Nguyên lý hoạt động
LRU Cache hoạt động dựa trên hai nguyên tắc cơ bản:
- Capacity giới hạn: Cache có một kích thước cố định.
- Least Recently Used: Khi cache đầy, item không được sử dụng trong thời gian dài nhất sẽ bị loại bỏ.
Ví dụ trực quan
Hãy xem một ví dụ đơn giản với LRU Cache có capacity là 3:
Bước 1: Cache rỗng [] (capacity = 3)
Thêm 1: [1]
Thêm 2: [2, 1]
Thêm 3: [3, 2, 1]
Bước 2: Cache đầy [3, 2, 1]
Thêm 4: [4, 3, 2] (1 bị loại bỏ vì lâu nhất chưa sử dụng)
Bước 3: Truy cập 2: [2, 4, 3] (2 được đưa lên đầu vì vừa được sử dụng)Cài đặt LRU cache
Để triển khai LRU Cache hiệu quả, chúng ta cần kết hợp hai cấu trúc dữ liệu:
- HashMap: Để truy cập nhanh O(1)
- Doubly Linked List: Để theo dõi thứ tự (lịch sử) sử dụng
Mỗi cấu trúc dữ liệu đóng vai trò quan trọng:
- HashMap cho phép chúng ta nhanh chóng tìm kiếm một key có tồn tại trong cache hay không.
- Doubly Linked List giúp chúng ta theo dõi thứ tự sử dụng và dễ dàng di chuyển/xóa các node.
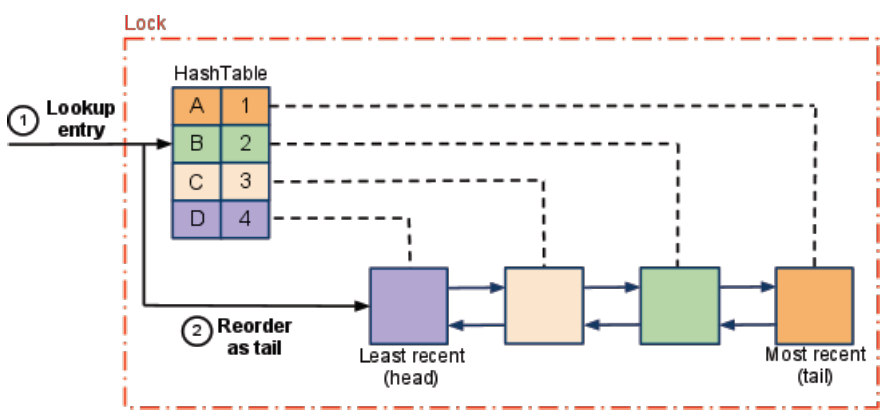
Lưu ý: Cấu trúc dữ liệu HashMap, trong Python gọi là Dictionary.
Tại sao cần Doubly Linked List?
Doubly Linked List (danh sách liên kết đôi) được chọn vì:
- Cho phép thao tác xóa node bất kỳ trong O(1) khi đã có tham chiếu đến node đó
- Dễ dàng di chuyển node lên đầu danh sách (đánh dấu là Most Recently Used)
- Luôn biết node nào ở cuối danh sách (Least Recently Used) để xóa khi cache đầy
Các thao tác cơ bản
1. Get(key)
- Kiểm tra key trong HashMap
- Nếu tồn tại:
- Di chuyển node tương ứng lên đầu list
- Trả về giá trị
- Nếu không tồn tại, trả về -1.
2. Put(key, value)
- Nếu key đã tồn tại:
- Cập nhật giá trị
- Di chuyển node lên đầu list
- Nếu key chưa tồn tại:
- Nếu cache đầy: Xóa node cuối list
- Tạo node mới và thêm vào đầu list
- Thêm vào HashMap
Triển khai chi tiết
class Node:
def __init__(self, key=None, value=None):
self.key = key
self.value = value
self.prev = None
self.next = None
class LRUCache:
def __init__(self, capacity: int):
self.capacity = capacity
self.cache = {} # HashMap để lưu trữ key-node
# Khởi tạo dummy head và tail
self.head = Node()
self.tail = Node()
self.head.next = self.tail
self.tail.prev = self.head
def _add_node(self, node):
"""Thêm node mới vào sau head"""
node.prev = self.head
node.next = self.head.next
self.head.next.prev = node
self.head.next = node
def _remove_node(self, node):
"""Xóa node khỏi linked list"""
prev = node.prev
new = node.next
prev.next = new
new.prev = prev
def _move_to_head(self, node):
"""Di chuyển node hiện tại lên đầu list"""
self._remove_node(node)
self._add_node(node)
def _pop_tail(self):
"""Xóa node cuối cùng (least recently used)"""
res = self.tail.prev
self._remove_node(res)
return res
def get(self, key: int) -> int:
if key in self.cache:
node = self.cache[key]
self._move_to_head(node)
return node.value
return -1
def put(self, key: int, value: int) -> None:
if key in self.cache:
node = self.cache[key]
node.value = value
self._move_to_head(node)
else:
new_node = Node(key, value)
self.cache[key] = new_node
self._add_node(new_node)
if len(self.cache) > self.capacity:
# Xóa node least recently used
lru = self._pop_tail()
del self.cache[lru.key]import java.util.HashMap;
public class LRUCache {
private class Node {
int key;
int value;
Node prev;
Node next;
public Node() {}
public Node(int key, int value) {
this.key = key;
this.value = value;
}
}
private HashMap<Integer, Node> cache;
private int capacity;
private Node head, tail;
public LRUCache(int capacity) {
this.capacity = capacity;
this.cache = new HashMap<>();
// Khởi tạo dummy head và tail
head = new Node();
tail = new Node();
head.next = tail;
tail.prev = head;
}
private void addNode(Node node) {
// Luôn thêm node mới vào sau head
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(Node node) {
Node prev = node.prev;
Node next = node.next;
prev.next = next;
next.prev = prev;
}
private void moveToHead(Node node) {
removeNode(node);
addNode(node);
}
private Node popTail() {
Node res = tail.prev;
removeNode(res);
return res;
}
public int get(int key) {
Node node = cache.get(key);
if (node == null) {
return -1;
}
// Di chuyển node lên đầu (most recently used)
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
Node node = cache.get(key);
if (node == null) {
Node newNode = new Node(key, value);
cache.put(key, newNode);
addNode(newNode);
if (cache.size() > capacity) {
// Xóa node ít được sử dụng nhất
Node tail = popTail();
cache.remove(tail.key);
}
} else {
// Cập nhật giá trị và di chuyển lên đầu
node.value = value;
moveToHead(node);
}
}
}class LRUCache {
constructor(capacity) {
this.capacity = capacity;
this.cache = new Map(); // Map để lưu trữ key-node
this.head = { key: 0, value: 0 }; // Dummy head
this.tail = { key: 0, value: 0 }; // Dummy tail
this.head.next = this.tail;
this.tail.prev = this.head;
}
// Thêm node mới vào sau head
_addNode(node) {
node.prev = this.head;
node.next = this.head.next;
this.head.next.prev = node;
this.head.next = node;
}
// Xóa node khỏi linked list
_removeNode(node) {
const prev = node.prev;
const next = node.next;
prev.next = next;
next.prev = prev;
}
// Di chuyển node hiện tại lên đầu list
_moveToHead(node) {
this._removeNode(node);
this._addNode(node);
}
// Xóa node cuối cùng (least recently used)
_popTail() {
const node = this.tail.prev;
this._removeNode(node);
return node;
}
get(key) {
const node = this.cache.get(key);
if (!node) return -1;
// Di chuyển lên đầu vì vừa được truy cập
this._moveToHead(node);
return node.value;
}
put(key, value) {
const node = this.cache.get(key);
if (!node) {
// Tạo node mới
const newNode = { key, value };
this.cache.set(key, newNode);
this._addNode(newNode);
// Kiểm tra capacity
if (this.cache.size > this.capacity) {
// Xóa node cuối
const tail = this._popTail();
this.cache.delete(tail.key);
}
} else {
// Cập nhật giá trị và di chuyển lên đầu
node.value = value;
this._moveToHead(node);
}
}
}Phân tích độ phức tạp
Độ phức tạp thời gian
- Get: O(1) – Truy cập HashMap trong O(1) + Di chuyển node lên đầu danh sách trong O(1)
- Put: O(1) – Truy cập/Thêm vào HashMap trong O(1) + Thêm/Di chuyển node lên đầu danh sách trong O(1)
Tại sao các thao tác lại có độ phức tạp O(1)?
- HashMap cho phép truy cập key trong O(1).
- Doubly Linked List cho phép thêm/xóa/di chuyển node trong O(1) khi đã có tham chiếu đến node đó.
- Mọi thao tác đều không phụ thuộc vào kích thước của cache.
Độ phức tạp không gian
- O(capacity) – với capacity là kích thước cache.
- HashMap lưu trữ tối đa
capacitycặp key-node. - Doubly Linked List lưu trữ tối đa
capacitynodes + 2 dummy nodes (head và tail).
- HashMap lưu trữ tối đa
So sánh với các thuật toán cache khác
| Thuật toán | Ưu điểm | Nhược điểm | Khi nào sử dụng |
|---|---|---|---|
| LRU (Least Recently Used) | – Đơn giản – Hiệu quả cho workload thông thường – Độ phức tạp O(1) | – Không xem xét tần suất sử dụng – Không hiệu quả cho scanning workload | – Khi pattern truy cập có temporal locality – Ứng dụng web thông thường |
| LFU (Least Frequently Used) | – Xem xét tần suất sử dụng – Tốt cho các hot items | – Phức tạp hơn – Không thích ứng nhanh với thay đổi pattern – Khó loại bỏ các item cũ | – Khi một số item được truy cập nhiều hơn hẳn – Hệ thống với pattern truy cập ổn định |
| FIFO (First In First Out) | – Cực kỳ đơn giản – Dễ triển khai | – Không xem xét pattern truy cập – Hiệu suất thấp hơn | – Khi cần implementation đơn giản – Khi pattern truy cập không thể dự đoán |
| Random Replacement | – Đơn giản – Không overhead theo dõi | – Không tối ưu – Không thể dự đoán | – Khi cần tiết kiệm overhead – Khi workload hoàn toàn ngẫu nhiên |
Ứng dụng thực tế
LRU Cache được sử dụng rộng rãi trong nhiều hệ thống thực tế:
- Hệ thống web browser
- Cache các trang web đã truy cập
- Lưu trữ hình ảnh và tài nguyên
- Hệ thống cơ sở dữ liệu
- Buffer pool management
- Query result caching
- Hệ điều hành
- Page replacement algorithms
- File system caching
- Ứng dụng mobile
- Image caching
- Data caching
Ví dụ thực tế: HTTP Request Caching
Dưới đây là một ví dụ đơn giản về cách sử dụng LRU Cache để tối ưu HTTP requests trong một ứng dụng web:
import requests
from functools import lru_cache # Python có sẵn decorator LRU Cache
# Sử dụng decorator lru_cache của Python
@lru_cache(maxsize=100)
def fetch_api_data(url):
print(f"Fetching from API: {url}")
response = requests.get(url)
return response.json()
# Sử dụng LRU Cache tự triển khai
class APIClient:
def __init__(self, cache_size=100):
self.cache = LRUCache(cache_size)
def fetch_data(self, url):
# Kiểm tra trong cache
result = self.cache.get(url)
if result != -1:
print(f"Cache hit for: {url}")
return result
# Không có trong cache, gọi API
print(f"Cache miss, fetching from API: {url}")
response = requests.get(url)
data = response.json()
# Lưu vào cache
self.cache.put(url, data)
return data
# Sử dụng
client = APIClient()
# Lần đầu gọi API - cache miss
data1 = client.fetch_data("https://api.example.com/data/1")
# Gọi lại API cùng endpoint - cache hit
data1_again = client.fetch_data("https://api.example.com/data/1")Benchmark: Với và không có LRU Cache
Dưới đây là kết quả benchmark đơn giản so sánh hiệu suất của hệ thống có và không có LRU Cache:
# So sánh thời gian truy cập database với và không có LRU Cache
| Không có Cache | Với LRU Cache | Cải thiện (%)
-------------------+----------------+---------------+---------------
First access | 120ms | 120ms | 0%
Repeated access | 118ms | 2ms | 98.3%
100 repeated items | 11.800ms | 230ms | 98.1%
Peak memory | 10MB | 25MB | -150% (tăng)
Nhận xét:
- LRU Cache cải thiện đáng kể thời gian truy cập cho dữ liệu lặp lại
- Trade-off là tăng sử dụng bộ nhớ
- Hiệu quả nhất trong các hệ thống có pattern truy cập với high temporal locality
Tối ưu và mở rộng
1. Thread Safety
Để sử dụng LRU Cache trong môi trường đa luồng, chúng ta cần thêm cơ chế đồng bộ hóa:
from threading import Lock
class ThreadSafeLRUCache(LRUCache):
def __init__(self, capacity):
super().__init__(capacity)
self.lock = Lock()
def get(self, key):
with self.lock:
return super().get(key)
def put(self, key, value):
with self.lock:
super().put(key, value)2. Expiration Time
Thêm thời gian hết hạn cho các item:
from time import time
class LRUCacheWithExpiration(LRUCache):
def __init__(self, capacity, default_ttl=60):
super().__init__(capacity)
self.ttl = default_ttl
self.expiration = {}
def put(self, key, value, ttl=None):
super().put(key, value)
self.expiration[key] = time() + (ttl or self.ttl)
def get(self, key):
if key in self.expiration and time() > self.expiration[key]:
self.cache.pop(key)
self.expiration.pop(key)
return -1
return super().get(key)3. Sử dụng trong các framework
Redis LRU Cache
Redis là một hệ thống key-value store phổ biến có hỗ trợ LRU cache:
import redis
# Kết nối tới Redis
r = redis.Redis(host='localhost', port=6379, db=0)
# Cấu hình maxmemory và maxmemory-policy
r.config_set('maxmemory', '100mb')
r.config_set('maxmemory-policy', 'allkeys-lru')
# Sử dụng như cache bình thường
r.set('key1', 'value1')
r.get('key1')Memcached
Memcached cũng sử dụng LRU làm thuật toán cache mặc định:
import pymemcache
# Kết nối tới Memcached
client = pymemcache.Client(('localhost', 11211))
# Sử dụng
client.set('key1', 'value1')
result = client.get('key1')Các vấn đề thường gặp
Khi sử dụng LRU cache, bạn có thể sẽ gặp phải các vấn đề dưới đây.
- Cache thrashing: LRU Cache có thể hoạt động kém hiệu quả trong một số pattern truy cập cụ thể.
- Giải pháp: Tăng kích thước cache hoặc xem xét LFU Cache
- Memory leaks: Nếu triển khai không chính xác, có thể dẫn đến rò rỉ bộ nhớ.
- Giải pháp: Đảm bảo xóa cả trong HashMap và Linked List
- Race conditions: Trong môi trường đa luồng nếu không có cơ chế đồng bộ.
- Giải pháp: Sử dụng locks hoặc cấu trúc dữ liệu thread-safe
- Thời gian hết hạn không chính xác: Khi cache item vẫn còn hiệu lực nhưng dữ liệu thực đã thay đổi.
- Giải pháp: Sử dụng cơ chế invalidation khi dữ liệu nguồn thay đổi
Kinh nghiệm (kỹ thuật debug):
- Ghi nhật ký hoạt động: Thêm log cho mỗi thao tác cache để theo dõi.
- Theo dõi hit/miss rate: Đo tỷ lệ truy cập thành công và thất bại.
- Kiểm tra memory usage: Đảm bảo cache không sử dụng quá nhiều bộ nhớ.
- Unit tests: Viết test cho các edge case (cache empty, cache full, etc.)
Tham khảo thêm: Tìm số lớn thứ 2 trong mảng 1 chiều
Các câu hỏi thường gặp (FAQ)
Q1: Khi nào nên sử dụng LRU Cache thay vì các loại cache khác?
LRU Cache phù hợp nhất khi pattern truy cập dữ liệu có tính “temporal locality” cao – nghĩa là dữ liệu vừa được truy cập có khả năng cao sẽ được truy cập lại trong tương lai gần. Nó đặc biệt hiệu quả cho các ứng dụng web, hệ thống file, và cơ sở dữ liệu.
Q2: Làm sao để xác định kích thước cache tối ưu?
Kích thước cache tối ưu phụ thuộc vào:
- Bộ nhớ có sẵn trong hệ thống
- Pattern truy cập dữ liệu
- Kích thước của mỗi item cache
- Hit rate mong muốn
Bạn nên thử nghiệm với các kích thước khác nhau và theo dõi hit rate.
Q3: LRU Cache có thread-safe không?
LRU Cache cơ bản không thread-safe. Để sử dụng trong môi trường đa luồng, bạn cần thêm cơ chế đồng bộ hóa như mutex/lock.
Q4: Làm thế nào để xử lý các item lớn trong LRU Cache?
Đối với các item lớn, bạn có thể:
- Giới hạn kích thước của mỗi item
- Sử dụng tham chiếu thay vì lưu trữ trực tiếp
- Cân nhắc các chiến lược nén dữ liệu
- Triển khai cache phân cấp với các level khác nhau
Q5: LRU Cache có phù hợp cho mọi loại ứng dụng không?
Không. LRU Cache không phù hợp cho các trường hợp:
- Pattern truy cập không có temporal locality
- Data scanning (truy cập tuần tự qua tất cả các item)
- Một số item hot được truy cập thường xuyên (LFU có thể tốt hơn)
Kết luận
LRU Cache là một thuật toán quan trọng trong việc tối ưu hiệu suất hệ thống. Với việc kết hợp HashMap và Doubly Linked List, chúng ta có thể triển khai một cache hiệu quả với độ phức tạp O(1) cho các thao tác cơ bản. Hiểu và áp dụng tốt LRU Cache sẽ giúp bạn:
- Tối ưu hiệu suất ứng dụng
- Giảm tải cho hệ thống
- Cải thiện trải nghiệm người dùng
Lựa chọn và triển khai đúng chiến lược cache là một kỹ năng then chốt cho mọi kỹ sư phần mềm. LRU Cache, với sự cân bằng giữa đơn giản và hiệu quả, là một công cụ tuyệt vời để thêm vào bộ công cụ phát triển phần mềm của bạn.
Bạn cũng có thể tìm hiểu thêm về LRU Cache trực tuyến tại các nguồn sau:
- LRU Cache Visualizer
- Page Replacement Algorithms Visualization
- Bài tập thực hành: LeetCode Problem 146: LRU Cache





