
Thuật toán CNN trong xử lý ngôn ngữ tự nhiên
Thuật toán CNN trong xử lý ngôn ngữ tự nhiên là nội dung cùa bài viết này. Tác giả của blog Nguyễn Văn Hiếu đã tìm được một bài viết rất hay. Bài viết này sẽ giúp bạn có những cái nhìn tổng quan về thuật toán CNN.
Thuật toán CNN đã cho thấy sự thành công trong một số bài toán phân loại văn bản. Trong [1], tác giả đã đưa ra một mô hình CNN đơn giản với việc điều chỉnh vài siêu tham số và sử dùng một pre-train word2vec. Cho thấy kết quả cực kỳ tốt. Giải pháp này đã giúp cải thiện kết quả của 4 trên tổng số 7 bài toán trong NLP.
Tuy nhiên, khi học cách áp dụng CNN vào word embeddings. Việc lần theo kích thước của các ma trận thường dễ gây nhầm lẫn và khó hiểu. Vì vậy, bài viết này sẽ giúp bạn hiểu cách CNN giải quyết bài toán phân loại văn bản. Mình sẽ tập trung vào lý giải sự thay đổi kích thước của các ma trận ở từng bước. Tôi sẽ sử dụng một mạng CNN với đầu vào là một câu văn có 7 từ, với số chiều của word embeddings là 5. Đơn giản chỉ là một ví dụ giúp bạn hiểu thôi. Và các ví dụ này được lấy từ [2].
NỘI DUNG BÀI VIẾT
Mô hình thuật toán CNN

Ảnh này được lấy từ [2], với các #hash-tags được thêm vào giúp các bạn dễ hình dung hơn. Tại mô hình Convolutional Neural Network này. Chúng tôi sử dụng 3 bộ lọc có các kích thước khác nhau: 2, 3, 4, và mỗi một kích thước, chúng tôi lại có 2 bộ lọc khác nhau. Các bộ lọc thực hiện nhân tích chập(convolution) lên ma trận của câu văn đầu vào và mỗi bộ lọc tạo ra một map lưu trữ các đặc trưng(features map). 6 map đặc trưng này từng map sẽ đi qua 1-max pooling – Tức là giá trị lớn nhất trong mỗi map đặc trưng sẽ được lưu lại.
Do vậy, một vector có 1 phần tử được tạo ra ở mỗi map đặc trưng. Sau đó, các giá trị này được nối lại với nhau tạo nên lớp áp chót ở trong hình. Và cuối cùng, kết quả này đi qua một hàm softmax và nhận được là một vector đặc trưng và dùng nó để dự đoán nhãn cho văn bản. Trong ví dụ này chúng tôi giả sử đây là bài toán phân loại văn bản chỉ có 2 lớp(binary classification) nên ở đây đầu ra chỉ có 2 trạng thái.
Tham khảo các bài viết về chủ đề machine learning tại đây
Giải thích các khái niệm
#sentence
Ví dụ trên sử dụng câu “I like this movie very much!”. Câu văn này có 6 từ và một dấu câu nữa. Dấu câu này ở đây sẽ được coi như là một từ. Như vậy là chúng ta có 7 từ tất cả. Ở đây tôi chọn số chiều của word vector là 5(tức là mỗi từ sẽ là một vector kích thước 1×5). Giả sử ta gọi d là số chiều của word vector. Như vậy kích thước ma trận của cả câu văn này là 7 x 5.
Giải thích thêm: Từ trong trường hợp này chính là một đặc trưng. Tùy bài toán mà người ta có coi dấu câu là đặc trưng hay không. Điều đó phụ thuộc vào việc nó có hữu dụng không. Tức là nếu lấy dấu câu thì có giúp tăng độ chính xác hay không. Do vậy, có nhiều trường hợp dấu câu sẽ bị loại bỏ.
#filters
Một tính chất mong muốn của thuật toán CNN bên xử lý ảnh là giữ được tính không gian 2 chiều theo góc quan sát của máy tính. Văn bản cũng có tính chất này như ảnh. Nhưng thay vì 2 chiều, văn bảnchỉ có một chiều và đó là các chuỗi từ liên tiếp. Ở ví dụ trên mỗi từ lại là một vector 5 chiều, do vậy ta cần cố định số chiều của bộ lọc cho phù hợp với số chiều của từ. Như vậy bộ lọc của chúng ta nên có kích thước (? x 5). Dấu ? thể hiện số từ(số hàng) mà chúng ta muốn lấy vào.
Ở bức hình trên, #filters là minh họa cho các bộ lọc. Đây không phải là bộ lọc để lọc bỏ các phần tử khỏi ma trận bị lọc. Điều này sẽ được giải thích kỹ hơn ở đoạn tiếp theo. Ở đây, tác giả sử dụng 6 bộ lọc, các bộ lọc được sử dụng có kích thước (2, 3, 4) từ.
#featuremaps
Trong đoạn này, chúng tôi sẽ từng bước giải thích cách bộ lọc nhân tích chập(convolutions / filtering). Tôi sẽ làm với vài số đầu tiên và sau đó bạn có thể dễ dàng hiểu và tự làm được.
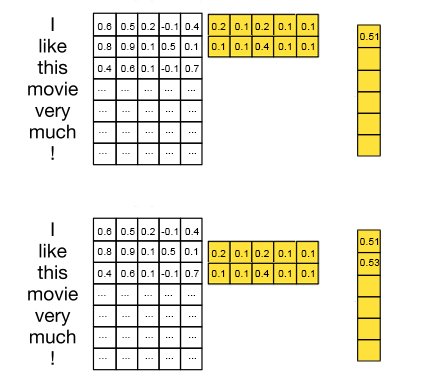
Ảnh phía trên thực hiện việc tính toán cho bộ lọc có kích thước là 2(2 từ). Với giá trị đầu tiên, bộ lọc màu vàng kích thước 2 x 5 thực hiện nhân từng thành phần với 2 hàng đầu tiên của văn bản(I, like).
Nó thực hiện bằng cách:
0.51 = 0.6 x 0.2 + 0.5 x 0.1 + 0.2 x 0.2 + ... + 0.1 x 0.1.
Tiếp theo với giá trị thứ 2, bộ lọc màu vàng giữ nguyên nhưng lần này nhân tích chập với ma trận văn bản của 2 từ (like, this) theo cách tương tự:
0.53 = 0.8 x 0.2 + 0.9 x 0.1 + ... + 0.7 x 0.1.
Cứ như vậy, ma trận bộ lọc(màu vàng) sẽ lùi xuống một dòng cho đến khi hết ma trận văn bản. Như vậy ma trận kết quả sẽ có kích thước là (7-2 + 1 x 1) = (6 x 1).
Để bảo đảm giá trị của map đặc trưng, chúng ta cần sử dụng một activation function( vd. ReLU). Áp dụng ReLU vẫn cho chúng ta ma trận có kích thước là 6 x1.
#1max
Lưu ý rằng kích thước của map đặc trưng phụ thuộc vào ma trận văn bản và ma trận bộ lọc. Nói cách khác, map đặc trưng sẽ có kích thước thay đổi chứ không cố định. Để đưa ma trận đặc trưng này về kích thước như nhau. Hoặc trong nhiều trường hợp người ta chỉ muốn giữ lại các đặc trưng tiêu biểu. Chúng ta có thể sử dụng max-pooling để lấy ra các giá trị lớn nhất trong map đặc trưng. Điều này giúp giảm chiều dữ liệu, tăng tốc độ tính toán.
Trong ví dụ này, tôi sử dụng 1-max-pooling. Tức là lấy ra 1 giá trị lớn nhất trong từng map đặc trưng. Việc này giúp ta có ma trận output có cùng kích thước. Ở đây kích thước sau khi áp dụng #1max là (1×1). Như vậy, ta chỉ lấy 1 đặc trưng trội nhất ở tất cả các lớp cnn để phục vụ cho bài toán.
#concat1max
Sau khi áp dụng 1-max pooling, chúng ta đã có những vector có kích thước cố định là 1×1 của 6 thành phần(bằng số bộ lọc). Vector cố định kích thước này sau đó được đưa vào một hàm softmax(lớp fully-connected) để giải quyết việc phân loại.
Như vậy, #concat1max thực hiện việc kết hợp tất cả các đặc trưng ở bước trước lại. Đưa ra một vector đặc trưng cuối cùng để đưa vào fully-connected. Tôi xin không giải thích kỹ về fully-connnected trong bài này. Sau đó, thường chúng ta sẽ qua một lớp softmax để đưa output về xác suất các nhãn có tổng bằng 1.
Hơn nữa, các độ đo lỗi ở giai đoạn phân loại này sau đó sẽ được đưa lại vào các tham số đóng vai trò là một phần của quá trình học để cải thiện độ chính xác cho mô hình.
Kết luận
Bài viết này làm rõ cách hoạt động của thuật toán CNN trên mô hình word embeddings và tập trung vào kích thước của các ma trận ở mỗi bước.
Tài liệu tham khảo
- Kim Y. Convolutional Neural Networks for Sentence Classification. 2014;
- Zhang Y, Wallace B. A Sensitivity Analysis of (and Practitioners’ Guide to) Convolutional Neural Networks for Sentence Classification. arXiv preprint arXiv:151003820. 2015; PMID: 463165
- http://www.joshuakim.io/understanding-how-convolutional-neural-network-cnn-perform-text-classification-with-word-embeddings/


![[Khóa học tensorflow] Bài 0 – Giới thiệu về khóa học Tensorflow](https://blog.luyencode.net/wp-content/uploads/2018/07/khoa-hoc-tensorflow-768x432.png)
![[Khóa học tensorflow] Bài 1 – Tổng quan về thư viện Tensorflow](https://blog.luyencode.net/wp-content/uploads/2018/07/tong-quan-ve-thu-vien-tensorflow-768x432.png)